
Op de 37e HL7 Working Group Meeting in Phoenix heb ik namens Stichting HL7 Nederland deelgenomen aan de FHIR Connectathon. Mijn doel was onze Nederlandse Basisgegevensset Zorg (BgZ) te vergelijken met de International Patient Summary (IPS). Niet alleen op functioneel niveau maar ook op het echte uitwisselformaat –de IPS in FHIR. Ik neem al enige tijd deel aan de IPS FHIR Working Group en dit was een mooie gelegenheid eens te kijken hoe ver we zijn – of niet natuurlijk.
Nederland gaat voorlopig nog geen gebruik maken van de FHIR IPS. Europees is er vooralsnog gekozen voor de Europese Patient Summary in CDA. Die lijkt veel op de IPS, maar is op details anders. Europa en de USA, en veel andere landen, zijn het er wel over eens dat we moeten op termijn migreren naar een en dezelfde standaard. Dat zal de FHIR IPS worden.
Het goede nieuws: een IPS aanmaken vanuit een BgZ is relatief eenvoudig, en redelijk compleet. Daarbij aangetekend, uiteraard, dat er op detailniveau wel de nodige verschillen zijn. Laten we eens de diepte induiken.
De BgZ versus de IPS
De BgZ is de Nederlandse “Patient Summary”: een samenvatting van de meest relevante medische gegevens van een patiënt. De BgZ is deels gebaseerd op internationale standaarden zoals C-CDA uit de USA en de Europese epSOS Patient Summary. De BgZ is in tegenstelling tot de IPS gebaseerd op Nederlandse zorginformatiebouwstenen (zibs) die internationaal niet veel gebruikt worden. In de praktijk vallen de verschillen mee, maar ze zijn er wel.

Internationaal staat de wereld ook niet stil. Bovengenoemde C-CDA en de epSOS PS zijn ook gebruikt als uitgangspunt voor de IPS. Dat leidt weer tot de nodige verschillen op detailniveau – voornamelijk verbeteringen door opgedane ervaring met het gebruik. Technisch is er ook een groot verschil: de IPS kent een CDA-variant maar ook een FHIR R4 variant. Die is er voor de Europese PS niet. Onze eigen BgZ kent wel een FHIR variant.
Nictiz heeft een fit-gap analyse gemaakt van de verschillen tussen de BgZ en de Europese PS op functioneel niveau: komen data-elementen en waardenlijsten overeen of niet. Zelf wilde ik een slag dieper kijken: wat zijn de verschillen op FHIR-niveau? Waarbij aangetekend dat mijn analyse verkennend en niet uitputtend is, zoals de fit-gap analyse wel is.
Aanpak
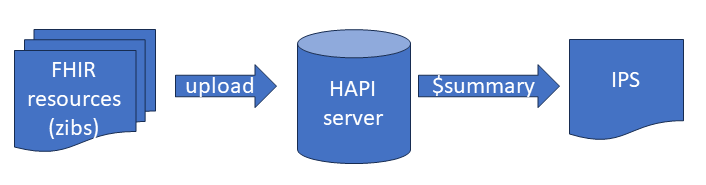
FHIR kent veel open source software, waaronder de HAPI server, die ook publiek toegankelijk is. Vanuit de Nederlandse FHIR projecten hebben we al veel voorbeelden in FHIR R4. Ook voor de BgZ, waarbij van een voorbeeldpatiënt een groot aantal zibs (zorginformatiebouwstenen) beschikbaar zijn als FHIR R4 resources. Deze FHIR-zibs kun je uploaden naar een FHIR server. Ik heb alle FHIR-zibs van de BgZ van een voorbeeldpatiënt met een Python script naar HAPI overgebracht met de FHIR update operation. HAPI controleert daarbij of de inhoud deugdelijk is. Na het uploaden van de voorbeeldpatiënt functioneert de HAPI server dus als een FHIR database waarmee we de patiëntgegevens kunnen bevragen.
Zonder inspanning gaat het niet: het is geen kwestie van uploaden en klaar, Met 2 dagen FHIR Connectathon en zo’n 3 dagen eromheen had ik een BgZ testset omgezet naar een FHIR IPS die zonder errors was, testend met de validatiesoftware van FHIR zelf. Er zijn dus wel aanpassingen nodig aan de BgZ.
Intermezzo: hoe werkt het
HAPI heeft nog niet zo lang de $summary operation: een uitvraag waarbij vanuit de FHIR resources die op de server aanwezig zijn, een IPS wordt gegenereerd. Daarbij wordt de hele documentstructuur van de IPS aangemaakt maar worden ook de narratieve secties gevuld.
IPS secties kennen naast gestructureerde gegevens ook een tekstuele weergave in HTML, die getoond kan worden aan de gebruiker. De IPS viewers die er zijn maken daar vaak gebruik van. Na het aanmaken van de patient op HAPI, kan de IPS dus direct opgehaald worden met:
https://hapi.fhir.org/baseR4/Patient/nl-core-Patient-01/$summary
(De HAPI testserver wordt regelmatig ververst, het is dus goed mogelijk dat dit voorbeeld niet meer te zien is. Het voorbeeld is hier ook te vinden.)
Deze IPS kan direct getoond worden in een IPS viewer. Voor wie dit na wil spelen: klik boven op de pagina op “Raw JSON”, of “Raw”. Kopieer de hele pagina. Ga dan naar: https://www.ipsviewer.com/ en plak de IPS in de tekstbox. Vervolgens kun je de IPS, die is omgezet uit de BgZ, zien in de viewer. De IPS kan getoond worden als FHIR Entries (de gestructureerde gegevens) of als FHIR Narrative (de door HAPI gegenereerde tekst als HTML). Hier een stuk van de BgZ zoals dat te zien is in de IPSviewer.

Een andere viewer is: https://ps-ca-renderer.apibox.ca/
Bevindingen
De structuur van de IPS
De BgZ in Nederland wordt samengesteld met FHIR queries. Kort gezegd: je vraagt bij een bron de allergieën uit, dan de problemen, dan de labuitslagen et cetera en wanneer je klaar bent heb je een complete BgZ. De IPS werkt anders: dat is een FHIR Document, en alles zit daar al in. Het maakt uit bij afwijkende bevindingen, zoals: voor deze patiënt zijn er geen allergieën bekend. In de IPS kan dat toegevoegd worden in het document. En dan niet alleen als “ik heb niks gevonden”, maar ook als positieve uitspraak: “de patiënt is bevraagd door arts X op datum Y, en er zijn geen allergieën bekend”. De BgZ kan dat niet zo eenvoudig. (Het is wel al langer een bekend en openstaand issue.)

De IPS is – omdat het een document is – ook eenvoudiger te bewaren, en eenvoudiger uit te wisselen over andere infrastructuren, zoals IHE XDS/XCA – appeltje eitje daar een IPS in op te nemen, maar met de huidige BgZ gaat dat niet. De eerlijkheid gebiedt wel te zeggen dat queries en documents beiden voor- en nadelen hebben.
Omdat de IPS een document is, is er ook een manier om een server te vragen: “geef mij een IPS”. Dat heet de $summary operation, en de FHIR server stelt dan een IPS samen op basis van wat er in die server bekend is. De open source HAPI server heeft die operation, en die wordt in het begin van deze blog ook gebruikt om de BgZ om te zetten naar een IPS.
Een ander punt is de tekstuele weergave in de IPS. Een FHIR Document (net als de oudere standaard CDA) kent bij iedere sectie een tekstueel blok, en een blok met gecodeerde gegevens. Dat tekstuele blok is een variant van HTML, en kan gewoon in een webbrowser getoond worden. Makkelijk, want zo kan de arts of patiënt de informatie altijd zien, ook als de applicatie die gebruikt wordt de gecodeerde gegevens niet ondersteund. Maar wanneer je alleen losse FHIR resources hebt die je met queries ophaalt, heb je helemaal geen tekstueel blok per sectie. De HAPI server lost dat op door een tekstblok per sectie te genereren. Dat is dan meestal een tabel met de meest essentiële gegevens uit de gecodeerde gegevens. Het werkt. Misschien zou een lokaal gegenereerd tekstblok per sectie nog beter kunnen zijn, maar eerlijk gezegd: steeds vaker worden die tekstblokken altijd gegenereerd uit de gecodeerde gegevens, ook in Nederland in onze BgZ. Het is dus meer de vraag of de aanpak van CDA en FHIR Documents met altijd-tekstblok-en-gecodeerde-gegevens niet zijn langste tijd gehad heeft.
Extensies en de zibs
In Nederland zijn de zibs de basis van de gegevensuitwisseling in de zorg. In andere landen is dat niet zo. Vaak wordt gewerkt vanuit een “Implementation Guide” voor een specifiek domein, wat in de Engelstalige wereld vaak gebeurt, of vanuit een dataset zoals o.a. in Duitsland. Bij het omzetten van zibs naar FHIR resources blijkt dan ook vaak dat het niet helemaal past: er ontbreken bijvoorbeeld elementen die de zib kent in de FHIR resource. Dat hoeft geen heel groot probleem te zijn: FHIR kent “extensions” waarmee gegevens toegevoegd kunnen worden aan een FHIR resource.
Zie dit voorbeeld van de zib MedischHulpmiddel:

Een onderdeel van de zib is de lateraliteit: links, rechts of beide. Dat zit niet op die manier in de FHIR resource, en daarom wordt er een extensie gebruikt:

Zolang we in Nederland blijven werkt dat prima. Alleen: de IPS, en andere internationale standaarden, kennen die Nederlandse extensies helemaal niet. Dat leidt ertoe dat je de extensie ook helemaal niet ziet in een internationale toepassing op de IPS, en de toevoeging “Rechts” daar wegvalt.
Is dat erg? Dat hangt van de extensie af. In het ene geval gaat vrij essentiële informatie verloren, in het andere geval valt er mee te leven. Soms voegt een extensie alleen een Snomed code toe aan een HL7 code. Een ander mooi voorbeeld is de naam:

In Nederland kennen we een voorvoegsel bij de achternaam. Het FHIR voorbeeld hierboven ziet er prima uit in de IPS:

Maar dit is alleen omdat zowel de hele “family” string gevuld is met de componenten (“van Putten-van der Giessen”). En dat is in Nederland niet verplicht: de “family” string leeg laten en alleen de onderdelen “van”, “Putten” etc. vullen mag. En als je alleen die onderdelen vult, maar niet de samengestelde achternaam, blijft die in een IPS toepassing leeg. Voor het aanmaken van een correcte IPS is dus wel wat te doen: bijvoorbeeld vullen van de samengestelde familienaam als die leeg is uit de componenten, en dito voor veel andere extensies.
Er zitten heel veel extensies in onze Nederlandse FHIR resources, grotendeels het gevolg van het eigen model wat de zibs kennen. Dat biedt voordelen in Nederland. Internationaal betaal je daar weer een prijs voor: deze extensies gaan verloren bij internationale uitwisseling zonder aanvullende maatregelen.
Verschillen in de inhoud
De IPS en de BgZ verschillen ook in inhoud. Nictiz heeft een fit-gap analyse op detailniveau gemaakt. Om een paar punten op te noemen: de BgZ kent een sectie “Alerts”, waarin bijvoorbeeld zaken staan als een MRSA-besmetting (een bacterie die resistent is tegen antibiotica): belangrijk, want zo’n patiënt wil je niet in je ziekenhuis zonder maatregelen, anders hebben spoedig alle patiënten die bacterie. De IPS kent dan weer een sectie “Zwangerschap” die de BgZ niet kent. Die zou relatief eenvoudig toe te voegen zijn, want we hebben in Nederland al uitgebreide standaarden rond geboorte.
Verder is er een belangrijk verschil, ook met de Europese PS: de IPS heeft een subset van Snomed (de Snomed IPS Free Set) beschikbaar gekregen. Snomed CT is een internationaal terminologiestelsel dat o.a. in Nederland veel gebruikt wordt, en essentieel is in onze uitwisselingen. Helaas wordt Snomed niet overal gebruikt en dat heeft er onder andere mee te maken dat Snomed niet gratis beschikbaar is. De Snomed IPS Free Set is dat wel, en die is pas ontstaan na de Europese PS. Die Free Set speelt dus een belangrijke rol in de IPS: veel waardenlijsten bestaan uit concepten uit de Free Set. In de Nederlandse BgZ (en de Europese PS) is daarmee nog geen rekening gehouden en er zitten dan ook verschillen in. Belangrijk is bij aanpassingen in terminologie in de BgZ, altijd goed naar de Free Set te kijken.
Vaak vallen de verschillen in de waardenlijsten tussen de BgZ en de IPS wel mee. Voor TabakGebruik hanteren beide 8 codes, waarvan 6 dezelfde. Voor de ernst van een allergie kent de zib 1 code meer dan de IPS. In dit soort gevallen is een mapping wel te vinden die in de conversie gebruikt kan worden zonder groot verlies van informatie.
Op een dieper niveau zijn er ook verschillen te vinden. Zowel de zibs als de IPS kennen een “Functionele of mentale status”. Bij de zib is ervoor gekozen deze te implementeren als een FHIR Observation. De IPS biedt hier de keuze tussen een FHIR Condition (de zib Probleem) of een FHIR ClinicalImpression. Uiteraard zou het goed zijn hier altijd te kijken naar keuzes die internationaal gemaakt worden. Bij het omzetten van de BgZ naar de IPS gaat de sectie “Functionele of mentale status” dus verloren. Om die te behouden zouden de FHIR Observations in die sectie eerst omgezet moeten worden naar ClinicalImpression of Condition.
Medicatie

Een lastig verhaal is medicatie. De BgZ2017 kent drie medicatiebouwstenen: MedicatieAfspraak (wat de arts voorschrijft), Toedieningsafspraak (precieze instructie van de apotheker) en MedicatieGebruik (wat de patiënt echt gebruikt). Het is me in Phoenix bij een aantal medicatiebouwstenen niet gelukt die zodanig in de IPS op te nemen dat er geen foutmeldingen optraden. Op zich niet heel vreemd, ik heb een weekend en wat uurtjes daarna eraan gewerkt, dat is niet veel, en met wat meer tijd en moeite kom je vast verder. Het is wel het enige onderdeel waar ik hier tegen aan liep.
Fundamenteler zijn de extensies in medicatie. In medicatie is er een extensie voor de hele doseerinstructie als tekst: “Vanaf 1 september 2012 gedurende 5 dagen 1x per dag om 8uur 40 mg (=1 st)”. Er zijn nog wel meer extensies in medicatie met nuttige informatie. In een internationale applicatie als de IPSviewer valt het allemaal weg. Ook een narrative (tekstblok) per medicatiebouwsteen helpt niet veel: de IPSviewer (en andere applicaties) laten ofwel de narrative van de hele sectie zien ofwel de gestructureerde inhoud, waarin de Nederlandse extensies dus ontbreken. Voor het internationaal uitwisselen van medicatie met de IPS is nog wel wat werk te verrichten. De aanpak: in een FHIR server stoppen en een IPS genereren alleen is hier niet voldoende. Voor medicatie is het dus nodig de Nederlandse resources met een stukje custom software om te zetten naar de internationale. Dat is op zich niet erg, en het zal op meer plaatsen in de BgZ wel nodig zijn.
En de taal dan?
Hierboven was het al te zien, een doseerinstructie als: “Vanaf 1 september 2012 gedurende 5 dagen 1x per dag om 8uur 40 mg (=1 st)”. Dat zal een arts in Frankrijk of Polen niet zonder meer begrijpen. Veel van de inhoud kan wel “vertaald” worden. De meting “Lichaamsgewicht” is bijvoorbeeld gecodeerd met de LOINC code “29463-7”, en de Engelse vertaling is bekend: “Body weight”. Eigenlijk is alles wat gecodeerd is in principe te vertalen. De zibs, en dus onze BgZ, kennen wel veel tekstuele toelichtingen. Die zijn niet te vertalen op basis van coderingen. Vertaalsoftware op vrije tekst kan steeds meer; wanneer dit gebruikt kan worden hangt van de toepassing af. Voor ingrijpende medische handelingen zal dit nog niet het geval zijn, voor alledaagse hulpverlening waarschijnlijk wel. Maar ook zonder het vertalen van vrije tekst is de IPS al een zeer nuttig overzicht van essentiële medische gegevens in een internationale context.
Conclusie
Er is goed nieuws: zonder bijzonder veel inspanning is, door onze zibs te uploaden in een FHIR server, met de $summary operation een heel behoorlijke IPS te maken. Die is zeker niet perfect, er zijn de nodige hoeken die bijgeschaafd moeten worden maar in wezen is het een overzichtelijke inspanning. Met name voor de secties Medicatie en Functionele en mentale status is nog wel werk nodig. Dat betekent dat internationaal delen van een IPS met standaardsoftware van FHIR, een te overzien aantal aanpassingen, vanuit de BgZ mogelijk is.
Voorlopig ziet het er naar uit dat we daar in Nederland niet direct mee te maken hebben omdat Europa eerst aansluit op de wat oudere Europese PS die nog gebaseerd is op CDA. Maar mijn doel op de HL7 WGM in Phoenix was te kijken hoe ver we afdrijven van het einddoel waar ook Europa naar toe wil: de IPS in FHIR. Dat lijkt mee te vallen. Wel een punt van zorg zijn de vele Nederlandse extensies: die zullen internationaal niet begrepen worden. Er zijn dan twee routes denkbaar: bij conversie naar de IPS die Nederlandse extensies – waar mogelijk – omzetten naar iets wat internationaal wel begrepen wordt. Of dit soort extensies zoveel mogelijk vermijden, in ieder geval in de BgZ. Ook dat vergt een lange adem: voor zibs2017 en zibs2020 kan dat niet meer. Het zou wel een belangrijk punt van aandacht moeten zijn bij latere versies van de zibs.