
De Nederlandse zorginformatie beweegt hard richting ZorgInformatieBouwstenen: de ZIBS. Het idee is eenvoudig: alle zorginformatie die voor hergebruik in aanmerking komt, wordt eenmalig op eenduidige wijze vastgelegd bij de bron, met dezelfde ZIBS. Zo hoeft alles maar een keer ingevoerd te worden. De ZIBS worden vervolgens uitgewisseld, en iedereen maakt gebruik van dezelfde data.
De werkelijkheid is weerbarstiger. Voor de duidelijkheid: ik vind de ZIBS een geweldig idee, en dit is zeker de richting waarin het in de zorg ICT heen moet. Maar tussen de ZIBS en de werkelijkheid zit vaak veel licht. Een paar voorbeelden.
Roken
Er is een zorginformatiebouwsteen ‘Tabakgebruik’:
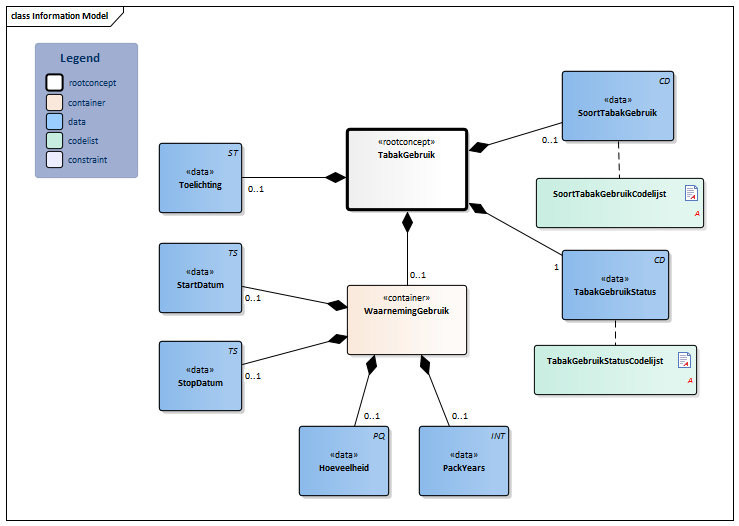
Hiermee kan in detail het rookgedrag worden vastgelegd. Met “SoortTabakGebruik” wordt vastgelegd wat iemand rookt (sigaretten, sigaren, pijp etc.) en met “TabakGebruikStatus” het rookgedrag (rookt dagelijks, rookt soms, rookte vroeger, niet-roker etc.). Er kan ook een “Hoeveelheid” bij (30 sigaretten per week, 100 gram shag etc.)
Wanneer we de ZIB willen gebruiken in de geboortezorg, lopen we direct tegen een probleem aan. In de geboortezorg wordt al een gegeven “Rookgedrag” uitgewisseld. Daarin zitten waarden als: 1-1o, 11-20. Wat staat er niet bij. Hoe maken we daar een ZIB van? We kunnen wat sjoemelen en 1-10 als “5” in de ZIB opslaan, en 11-20 als “15”. Maar dat suggereert natuurlijk een nauwkeurigheid die de zorgverlener of zwangere nooit heeft geuit. Getallen aan laten passen door software is gewoon niet goed in het primaire proces .
We kunnen ook de knoop doorhakken en helemaal voor de ZIB gaan. Alle leveranciers moeten dan de verloskundige en gynaecologische systemen aanpassen, en we leggen voortaan de ZIB Tabakgebruik vast. Daarbij duikt een ander probleem op. De Rookgedrag lijst van de Geboortezorg kent nog twee categorieën: “gestopt vóór huidige zwangerschap” en “gestopt tijdens huidige zwangerschap”. Relevant bij zwangerschap, maar dit zit niet in de ZIB Tabakgebruik. We kunnen het ergens anders stoppen, buiten de ZIB, alleen is het rookgedrag, wat één handzaam lijstje was, dan opeens over twee lijsten verspreid. Een bijkomend probleem bij overstappen op de ZIB is dat gegevens uit het verleden niet meer goed te vergelijken zijn met het heden, omdat er iets anders wordt vastgelegd.
Scores
In de zorg worden veel scores gebruikt. B.v. de Apgar score voor pasgeboren kinderen. Daar is een ZIB van, en het werkt als volgt: de verloskundige of gynaecoloog geeft een 0, 1 0f 2 voor een aantal observaties van de pasgeborene zoals ademhaling, huidskleur etc. Deze worden opgeteld tot een totaalscore. 7 of hoger is een goede score, bij een lagere is aandacht of ingrijpen nodig. Er staan er 13 in de ZIBS.
Er is een probleem wanneer we scores die niet in de ZIBS staan in een ZIB willen gieten. Zulke scores zijn er heel veel: vele tientallen in de oncologie alleen al. De losse items kunnen we nog wel in de zorginformatiebouwsteen AlgemeneMeting stoppen: die is voor metingen of bepalingen waarvoor geen specifieke ZIB is. Alleen is er met ZIBS geen manier om de totaalscores en de losse bepalingen te groeperen in één Score-ZIB. De relatie tussen de items is dus zoek.
Uitgerekend

Voor laboratoriumbepalingen is – heel terecht – gekozen voor een ZIB met een testcode (uit LOINC, voor de soort test) en een uitslag, en niet voor een ZIB per labtest. Daar zijn er veel te veel van, en er komen regelmatig nieuwe bij. Prima opgelost dus.
Voor niet-laboratoriumbepalingen is er de AlgemeneMeting. Er staat: “Een algemene meting legt de uitkomst vast van een meting of bepaling die bij een patënt is uitgevoerd” en : “Afhankelijk van de soort meting bestaat de uitslag uit een waarde met eenheid of uit een gecodeerde waarde (ordinaal of nominaal) of uit een tekstuele uitslag.” Daar zijn ook een paar problemen mee.
Een paar andere gegevens van een patiënt:
- Datum laatste menstruatie: belangrijk in de verloskunde. Maar het is geen eenheid of gecodeerde waarde. Moet het dan maar als tekst? Terwijl het een datum is, en niet zomaar tekst? En het is ook geen meting, want de verloskundige meet niets.
- In de geboortezorg wordt ook vastgelegd of er sprake is van seksueel geweld, of huiselijk geweld. Daar speelt hetzelfde probleem: het is geen “meting”, maar een vraag. Het antwoord is “ja” of “nee”, geen eenheid en geen code. Het past dus niet echt in AlgemeneMeting.
- A terme datum: dat is de datum waarop de vrouw is “uitgerekend”. Die zit in de ZIB Zwangerschap, maar die is te onnauwkeurig voor geboortezorg. Daar wil men ook weten op basis waarvan de à terme datum bepaald is: de laatste menstruatie, een echoscopie etc. Wanneer we dan een AlgemeneMeting willen gebruiken, lopen we weer tegen het probleem van de scores aan: er is geen manier om twee gegevens (à terme datum en basis bepaling) “samen te voegen” in een ZIB.
Samenvattend: hoewel de AlgemeneMeting een nuttige ZIB is, is deze nog niet breed genoeg. Er is een “Algemene Bevinding” nodig, waarin niet alleen metingen passen maar ook andere bevindingen en vragen. Waar ook datums en ja/nee als antwoord kunnen. En belangrijk: waarin gegevens aan elkaar gerelateerd kunnen worden. Als dat er is, kan het meeste vastgelegd worden als een (specialisatie van) een ZIB.
Gewicht

Een wat kleiner probleem, maar toch goed om aan te geven hoe complex “verzibben” is. Gewicht, zou men denken, is toch wel een basisgegeven. Maar in de ZIB Lichaamsgewicht is gekozen voor LOINC code 29463-7 : “Body weight”. In het PWD van de Geboortezorg is gekozen voor LOINC code 3141-9: “Body weight Measured”. Is dit nu hetzelfde? Kunnen we het gewoon in de ZIB stoppen, en de ene LOINC code weggooien en de andere opnemen? Ook hier geldt weer: codes met toch een iets andere betekenis aan laten passen door computers is zelden een goed idee.
Bloedgroep
Iets soortgelijks speelt bij “Bloedgroep”. Daar is geen zorginformatiebouwsteen voor (toch een vrij algemeen gegeven, dus dat zou je wel verwachten). Bij ontbreken van een ZIB kunnen we kiezen uit Labuitslag of AlgemeneMeting. Wanneer er een lab onderzoek gedaan wordt, is LabUitslag natuurlijk logisch. Maar wanneer alleen de bloedgroep A, B of O wordt vastgelegd, is het complexer. Er zijn twee labonderzoeken in de Nederlandse Labcodeset: ABO en ABO+rhesus, en dus twee LOINC codes. In een systeem van de huisarts of verloskundige zal niet staan welke test is uitgevoerd, alleen A, B of O. Dan kunnen we dus geen LabUitslag gebruiken, omdat de LOINC code niet meer te achterhalen is. Rhesus is nog ingewikkelder. Wanneer alleen de rhesus-factor wordt doorgegeven, kan de LOINC-code voor ABO+rh niet gebruikt worden, omdat dan niet duidelijk is of het over ABO of rh gaat. De AlgemeneMeting is een oplossing. Lastig is dan alleen dat we de ene keer een Bloedgroep in de ZIB Labuitslag doen, en de andere keer in AlgemeneMeting. Geen echte standaardisatie.
Conclusie
Nogmaals, de ZIBS zijn een goed idee, en dit is de weg vooruit. Maar bij de praktijk van het omzetten van de huidige zorginformatie naar ZIBS, het “verzibben” zijn nog heel veel obstakels. Even alles nu opeens als ZIBS uitwisselen is niet realistisch. Het vereist een heel andere registratie, en heel veel aanpassingen in systemen. En – zoals betoogd – ook nog wel wat aanpassingen aan de ZIBS.
Is deze blog nuttig? Deel hem via LinkedIn, Twitter of anders!