
At the 37th HL7 Working Group Meeting in Phoenix I participated in the FHIR Connectathon on behalf of HL7 Netherlands. My goal was to transform our Dutch National Patient Summary (Basisgegevensset Zorg, BgZ) to an International Patient Summary (IPS). I have been participating in the IPS FHIR Working Group for some time now and this was a great opportunity to see how far we are – or aren’t – apart.
The Netherlands will not be using the FHIR IPS in the near future. At the European level, the European Patient Summary in CDA has been chosen for the time being. It is very similar to the IPS, but details differ. Europe and the USA, and many other countries, agree that we should eventually migrate to one and the same standard. That will be the FHIR IPS.
The good news: creating an IPS from a BgZ is relatively simple and reasonably complete. It should be noted, of course, that there are some differences at a detailed level. Let’s do a deep dive.
The BgZ versus the IPS
The BgZ is the Dutch ‘Patient Summary’: a summary of the most relevant medical data of a patient. The BgZ is partly based on international standards such as C-CDA from the USA and the European epSOS Patient Summary. In contrast to the IPS, the BgZ is based on our Dutch HealthCare Information Models (HCIMs) that are not widely used internationally. In practice the differences are overseeable, but there are some.

Internationally the world is not at a standstill either. The above-mentioned C-CDA and the epSOS PS have also been used as a starting point for the IPS. This in turn leads to differences at a detailed level – mainly improvements due to experience gained. Technically there is also a big difference: the IPS has a CDA variant but also an FHIR R4 variant. The latter does not exist for the European PS. Our national PS, the BgZ, does have an FHIR variant.
My approach
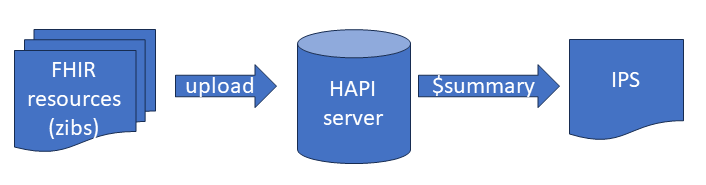
FHIR has a lot of open source software, including the HAPI server , which is also publicly accessible. For the BgZ we have a large number of HCIMs (our ‘HealthCare Information Models’) available as FHIR R4 resources. I transferred all those FHIR resources from the BgZ of an example patient to HAPI with a Python script using the FHIR update operation. HAPI checks whether the content is correct. After uploading the sample patient, the HAPI server functions as an FHIR database allowing us to query the patient data.
This is not without effort: it is not a matter of uploading and be done with. With 2 days of FHIR Connectathon and about 3 days extra effort it, I had converted our BgZ test set to an FHIR IPS that was error-free, testing with the validation software of FHIR itself. Adjustments are therefore required to the BgZ when converting it to an IPS.
How does this work
HAPI recently implemented the $summary operation: an operation which generates an IPS from the FHIR resources present on the server. The entire document structure of the IPS is created, and the textual representations of the IPS sections are also populated.
In addition to structured data, IPS sections also have a textual representation in HTML, which can be shown to the user. The available IPS viewers make use of those. After creating the patient on HAPI, the IPS can be retrieved immediately with:
https://hapi.fhir.org/baseR4/Patient/nl-core-Patient-01/$summary
(The HAPI test server is regularly refreshed, so it is quite possible that this example is no longer visible. The example can also be found here .)
This IPS can be displayed directly in an IPS viewer. For those who want to replay this: click on ‘Raw JSON’ at the top of the above HAPI page. Copy the entire page. Then go to: https://www.ipsviewer.com/ and paste the IPS into the text box. You can then see the IPS, which has been converted from the BgZ, in the viewer. The IPS can be displayed as FHIR Entries (the structured data) or as FHIR Narrative (the HAPI-generated section texts). Here is a piece of the BgZ as it can be seen in the IPSviewer:

Another viewer is: https://ps-ca-renderer.apibox.ca/
Findings
The structure of the IPS
The BgZ in the Netherlands is retrieved with FHIR queries. In short: you ask a source for the allergies, then the problems, then the lab results, etc. and when you are done you have a fully populated BgZ. The IPS works differently: it’s a FHIR Document, and everything is already in there. This matters if there are ‘absent’ findings, such as: there are no known allergies for this patient. In the IPS this can easily be added to the document as a special Allergy. And not only as ‘the server did not find anything’, but also as a positive statement: ‘the patient was interviewed by doctor X on date Y, and there are no known allergies’. The BgZ cannot do that so easily (this has been a known issue for some time.)

The IPS – because it is a document – is also easier to store and easier to exchange across other infrastructures, such as IHE. For completeness: the query and documents approaches both have their own advantages and disadvantages.
Since the IPS is a document one can also ask a server: ‘give me an IPS’. This is called the $summary operation where the FHIR server compiles an IPS based on what is known in that server. The open source HAPI server has the $summary operation, and I used it to convert the BgZ to an IPS.
Another point is the textual representation in the IPS. A FHIR Document (just like the older standard CDA) has a textual block for each section as well as a block with structured and coded data. The textual block is HTML, and can simply be displayed in a web browser. This allows the doctor or patient to read the information, even when their application does not support the structured data. But if you only have separate FHIR resources that are retrieved with queries, you have no textual block per section at all. The HAPI server solves this by generating a text block per section. This is usually a table with the most essential information from the structured data. It works. Perhaps a locally generated text block per section would be better, but to be honest: often those text blocks are generated from the structured data anyway – in the Netherlands more often than not, I’d guess.
Extensions and the HCIMs
In the Netherlands, the HCIMs are the core of data exchange in healthcare. This is not the case in other countries. When converting HCIMs to FHIR resources, it often turns out that they don’t quite fit: for example, elements that are in the HCIM are missing from the FHIR resource. That does not have to be a very big problem: FHIR has ‘extensions’ which allow data to be added to a FHIR resource.
Take this example of our HCIM MedicalDevice:

A part of the HCIM is the laterality: left, right or both. It is not a separate item in the FHIR resource, and that is why an extension is used (in the R4 FHIR DeviceUseStatement, this would be encoded as ‘right ear’, whereas the HCIMs require ‘right’ (‘Rechts’) and ‘ear’ (‘Oor’) as separate items):

As long as we stay in the Netherlands this works fine. Only: the IPS, and other international standards, do not recognize those Dutch extensions at all. One does not see the extension at all in an international application such as the IPSviewer, and the addition ‘Right’ (‘Rechts’) disappears.
Is this bad? It depends on the extension. In some cases quite essential information is lost, in the other case one could live with it. Sometimes an extension only adds a Snomed code to an equivalent HL7 code. Another example are Dutch family names:

In the Netherlands we sometimes have a prefix with our surnames. This FHIR example renders fine in the IPSviewer:

But this is only because the entire ‘family’ string is filled with the components (‘van Putten-van der Giessen’). And this is not mandatory in the Netherlands: leaving the ‘family’ string empty and only filling the parts ‘van’, ‘Putten’ etc. is allowed. And if you only fill in those parts, but not the composite surname, it will remain empty in an IPS application. Something needs to be done to create a correct IPS: filling the composite family name if it is empty from the components. FHIR allows this, so this is just a case of having stricter national guidelines here.
There are many extensions in our Dutch FHIR resources, largely the result of the HCIMs having a different data model. While this has advantages in the Netherlands, one pays a price internationally: these extensions are lost during international exchange without additional measures.
Differences in content
The IPS and the BgZ also differ in content. To mention a few points: the BgZ has an ‘Alerts’ section, which lists matters such as MRSA infections (a bacterium that is resistant to antibiotics): important, because you don’t want such a patient in your hospital without measures. The IPS on the other hand has a ‘Pregnancy’ section which the BgZ does not have. (This would be relatively easy to add because we already have extensive standards regarding birth in the Netherlands.)
Furthermore, there is an important difference: the IPS has made a subset of Snomed (the Snomed IPS Free Set) available. Snomed CT is an international terminology system that is widely used in the Netherlands, among others, and is essential in our exchanges. Unfortunately, Snomed is not used everywhere and this is partly due to the fact that Snomed is not available for free. The Snomed IPS Free Set is free, and plays an important role in the IPS: many value lists consist of concepts from the Free Set. This has not yet been taken into account in the Dutch BgZ (and the European PS) and there are differences. It is important to always look carefully at the Free Set when making changes to terminology in the BgZ.
The differences in the value lists between the BgZ and the IPS are often not too bad. Both use 8 codes for Tobacco Use, 6 of which are the same. The HCIM has 1 more code than the IPS for the severity of an allergy. In these types of cases, a mapping can be found that can be used in the conversion without major loss of information.
There are also differences to be found at a deeper level. Both the HCIMs and the IPS have a ‘Functional or mental status’. The HCIM has chosen to implement it as an FHIR Observation. The IPS offers the choice between a FHIR Condition and or a FHIR ClinicalImpression. Naturally, it would be good for us to always look at international choices. When converting the BgZ to the IPS, the ‘Functional or mental status’ section is therefore lost. To retain this, the FHIR Observations in that section should first be converted to ClinicalImpression of Condition (note: there currently is discussion within the IPS community whether Observations should not be part of this IPS section, so maybe the issue will be resolved from the IPS side).
Medication

A complicated story is medication. The BgZ has three medication HCIMs: Medication Agreement (what the doctor prescribes), Administration Agreement (precise instructions from the pharmacist) and Medication Use (what the patient actually uses). In Phoenix, I was unable to include a number of our medication resources in the IPS in such a way that no error messages occurred. Not very strange, I worked on it for a weekend and a few hours afterwards, which is not much, and with a little more time and effort one would probably make more progress. However, it’s the only section with the above ‘Functional or mental status’ which I could not fully transform.
More fundamental are the extensions in medication. In medication there is an extension for the entire dosing instruction as the text: ‘Vanaf 1 september 2012 gedurende 5 dagen 1x per dag om 8uur 40 mg (=1 st)’. There are many extensions in medication with useful information (whether it’s taken as instructed, why it is discontinued etc.). In an international application like the IPSviewer they all disappear. A narrative (text block) per medication building block also does not help much: the IPSviewer (and other applications) either show the narrative of the entire section or the recognized structured content, in which the Dutch extensions are not shown. There is still some work to be done regarding the international exchange of our medication HCIMs with the IPS. The approach: putting it all in an FHIR server and generating an IPS alone is not sufficient here. For medication it is necessary to convert Dutch resources to international resources with a piece of custom software. That in itself is not a problem, and it will be necessary in more places in the BgZ.
What about language?
As we saw above, Dutch HCIMs contain text such as: ‘Vanaf 1 september 2012 gedurende 5 dagen 1x per dag om 8uur 40 mg (=1 st)’. A doctor in France or Poland will not understand that. Much of the structured content can be translated. For example, our Dutch measurement ‘Lichaamsgewicht’ is coded with the LOINC code ‘29463-7’, and the English translation is known: ‘Body weight’. In fact, everything that is coded can in principle be translated. But the HCIMs, and therefore our BgZ, do have many plain text notes. These cannot be translated based on coding. Text translation software is ever more powerful but often still error-prone: whether automatic translation can be used depends on the use case. It will not yet be the case for surgical interventions, more so for everyday care. But even without automatic plain text translation, the IPS is a very useful overview of essential medical data in an international context.
Summary
The good news is: without too much effort, by uploading our HCIMs to a FHIR server, one can create a very decent IPS with the $summary operation from our national patient summary, the BgZ. It is certainly not perfect, and there are some corners that need to be refined. Work is still needed in particular for the Medication and Functional and mental status sections. This means that a conversion of our BgZ to an IPS with standard FHIR software, and an overseeable number of adjustments, is possible.
For the time being, it looks like we will not have to deal with this directly in the Netherlands because Europe will first connect to the somewhat older European PS that is still based on CDA. But my goal at the HL7 WGM in Phoenix was to see how far we are drifting from the final goal that Europe also wants to achieve: the IPS in FHIR. That doesn’t seem too far removed. The many Dutch extensions are a point of concern: they will not be understood internationally. There are two conceivable routes: when converting to the IPS, convert Dutch extensions – where possible – to something that is internationally understood. Or avoid these types of extensions as much as possible, at least in the BgZ. That also requires a lot of patience: this is no longer possible for our current HCIMs releases of 2017 and 2020. It should be an important point of attention in later versions of the HCIMs.